乽傊偨傟俛俙俽俬俠乿張棟宯傪堦捠傝嶌偭偰傒偰偐傜尒捈偟偰傒傞偲丄
偛偪傖偛偪傖偺埶懚娭學傪帩偭偨
僋儔僗廤抍偵側偭偰偟傑偄傑偟偨丅妛媺曵夡偺條憡傪掓偟偰偄傑偡丅乮傑偝偐両乯
偱傕丄偣偭偐偔僆乕僾儞僜乕僗偱傗偭偰峴偙偆偲峫偊偰偄傞偺偱丄
僋儔僗偺娭學傗撪梕偑堦懱偳偆側偭偰偄傞偺偐傪丄偙偙偱夝愢偟偨偄偲巚偄傑偡丅
杔偺彂偄偨僐乕僪傪撉傫偱傒傛偆偲偄偆儐僯乕僋側曽偑偄傜偭偟傖偄傑偟偨傜嶲峫偵偟偰壓偝偄傑偣丅
屻偱帺暘偱尒曉偟偰奐敪偺尒捠偟偵偡傞偨傔偵傕偙傟傪彂偒傑偡丅婎杮揑側偙偲偟偐傗偭偰側偄偺偱丄偳偺夝愢傕儘乕儗儀儖乮仼俀捠傝偺堄枴偱偹乯側僥乕儅偽偐傝偱偡丅
張棟偺棳傟偲丄僋儔僗柾條偺奣娤
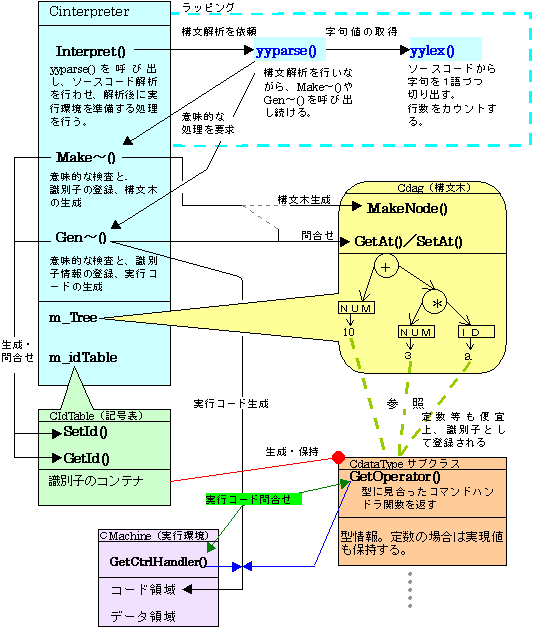
乽傊偨傟俛俙俽俬俠乿偑峴偆張棟偺棳傟偼丄傑偢CInterpreter偲偄偆僋儔僗偑懬庢傝栶偲側偭偰丄
條乆側僋儔僗傗娭悢偑楢実偟偁偭偰乮埶懚偟偁偭偰乯東栿張棟傪恑傔偰峴偒傑偡丅
僜乕僗僐乕僪偺嵟屻傑偱東栿偑廔傢傞偲丄
CMachine僋儔僗偺僆僽僕僃僋僩偑東栿寢壥偵廬偭偰丄張棟傪幚峴偟偰峴偒傑偡丅
偙傟傜偺張棟偺棳傟偼main()娭悢偺暥拞偱丄奺僆僽僕僃僋僩偵懳偡傞憖嶌偲偟偰婰弎偝傟偰偄傑偡丅
偙偙偱東栿帪偺奺僋儔僗傗娭悢偺張棟偺暘扴偵偮偄偰愢柧偟偰傒傑偡丅
main()偼CInterpreter偺Interpret()偲偄偆儊儞僶娭悢傪屇傃弌偟傑偡丄
偙偺娭悢偼僜乕僗僐乕僪傪撉傒恑傔偰丄
幚峴僐乕僪偺惗惉傗丄僨乕僞椞堟偺愝掕側偳丄幚峴帪娐嫬偺峔抸傪峴偄傑偡丅
僜乕僗僐乕僪偺帤嬪夝愅傗峔暥夝愅偼丄偦傟偧傟yylex()丄yyparse()偲偄偆娭悢偑峴偄傑偡偑丄
CInterpreter偼偙傟傜偺娭悢偲偺傗傝庢傝傪儔僢僺儞僌偟偰偍傝丄
CInterpreter偺儊儞僶娭悢Interpret()偺傒偐傜yyparse()偑屇偽傟丄yylex()偼yyparse()偺傒
偵傛傝屇偽傟偰偄傑偡丅
傑偨庒姳偺椺奜偼偁傝傑偡偑丄
偙傟傜偺娭悢偺撪晹偐傜CInterpreter偺儊儞僶埲奜偺娭悢偑
屇傃弌偝傟傞偙偲傕側偄傛偆側愝寁偵偟偰偄傑偡丅
yyparse()偼峔暥夝愅偺夁掱偱CInterpreter偺GenXXXX()傗丄
MakeXXXX()偲偄偆儊儞僶娭悢傪屇傃弌偟偰峴偒傑偡丅
偙傟傜偺娭悢偼奺乆偺峔暥夝愅偺抜奒偵懳墳偟偰丄幚峴娐嫬傪梡堄偡傞偨傔偺堄枴揑側張棟傪峴偆娭悢偱偡丅
CInterpreter偼峔暥夝愅偺夁掱偱丄慻崬傒僆僽僕僃僋僩m_Tree傪巊偭偰峔暥栘偺惗惉傪峴偭偰偄傑偡丅
偨偩偟尰僶乕僕儑儞偱偼峔暥栘偺僋儔僗壔偼晄姰慡偱偡丅
CInterpreter偼寁嶼幃傪張棟偡傞偨傔偵峔暥栘傪慻傒棫偰傑偡偑丄峔暥栘偼暥偺峔憿傑偱偼昞偟偰偍傜偢丄
堦偮堦偮偺寁嶼幃傪撉傒廔偊傞枅偵m_Tree偺撪梕偼弶婜壔壜擻偱偡丅
偙偆偟偨棟桼偐傜丄CInterpreter偑yyparse()偐傜屇傃弌偝傟傞儊儞僶娭悢偼丄
堄枴揑側専嵏偲峔暥栘偺惗惉傪峴偆MakeXXXX()偲丄
堄枴揑側専嵏偲幚峴僐乕僪偺惗惉傪峴偆GenXXXX()偲偄偆俀庬椶偺僶乕僕儑儞偵暘傟偰偄傑偡丅
CInterpreter偼幚峴僐乕僪椞堟偵彂偒弌偡奺乆偺僐儅儞僪傪丄
宆忣曬傪昞偡拪徾僋儔僗乽CDataType乿偺僒僽僋儔僗偵栤偄崌傢偣傞宍偱摼偰偄傑偡丅
奺CDataType僒僽僋儔僗偼CInterpreter偐傜僐儅儞僪偺俬俢傪庴偗庢傝丄
帺暘偺宆偵尒崌偭偨張棟傪峴偆娭悢偺億僀儞僞傪曉偟傑偡丅
偙傟傜偺娭悢偼CMachine撪偺慻崬傒僆僽僕僃僋僩偱偁傞僨乕僞乮僗僞僢僋乯椞堟偵懳偡傞憖嶌傪峴偄傑偡丅
娭悢偵傛偭偰偼僐乕僪椞堟側偳丄懠偺CMachine撪偺僆僽僕僃僋僩偲張棟偵昁梫側抣偺傗傝庢傝傪偟傑偡丅
偙傟傜偺娭悢偼CMachine偺儊儞僶偱偼偁傝傑偣傫偑丄CMachine偲屳偄偵嫮偔埶懚偟偰偄傞偨傔丄
CMachine偺儊儞僶娭悢偱偁偭偰傕偍偐偟偔側偄娭悢偱偡丅(儊儞僶娭悢偵偡傞偲丄宆偺庬椶傪憹傗偟偨帪丄
CMachine偺僀儞僞乕僼僃僀僗傪曄峏偡傞昁梫偑弌偰偔傞偺偱丄僋儔僗奜偺娭悢偲偟傑偟偨丅)
偙傟傜偺娭悢偼OP_HANDLER偲偄偆柤慜偱typedef偝傟偰偄偰丄
奺CDataType僒僽僋儔僗偺幚憰晹僼傽僀儖撪偵丄僼傽僀儖僗僐乕僾傪帩偮娭悢乮static乯偲偟偰掕媊偝傟偰偄傑偡丅
傑偨OP_HANDLER偼CMachine偺幚懱傊偺傾僋僙僗傪偦偺堷悢傗栠傝抣傪夘偟偰峴偆偺偱偼側偔丄
CDataType僒僽僋儔僗偺惷揑儊儞僶SetMachine()偵傛偭偰僼傽僀儖僗僐乕僾忋偵愝掕偝傟傞丄
CMachine僆僽僕僃僋僩傊偺億僀儞僞傪捠偠偰憖嶌傪峴偄傑偡丅
CDataType偺僒僽僋儔僗偼宆忣曬傪昞偡偲摨帪偵丄
幚憰偺忋偱偼CMachine偑嶌傝弌偡幚峴娐嫬偺堦晹偲摨嫃偟偰偄傑偡丅
傑偨丄暘婒傗儖乕僾側偳丄摿掕偺宆偲偼娭學側偄惂屼娭楢偺僐儅儞僪偼CMachine偺GetCtrlHandler()偵
栤崌偣傪偟偰偄傑偡丅
傑偨CInterpreter偼僜乕僗僐乕僪偐傜丄yylex()偑幆暿巕乮俬俢乯偲偟偰愗傝弌偟偨 暥帤楍偺庬椶傪敾抐偡傞張棟傪峴偭偰偄傑偡偑丄 偦偺忣曬傪暥帤楍偲嫟偵曐帩偟偰偍偔偺偑丄CIdTable宆偺僀儞僗僞儞僗偱偡丅 CInterpreter偼僜乕僗僐乕僪偐傜幆暿巕傪尒偮偗傞枅偵丄CIdTable僆僽僕僃僋僩偵 偦偺暥帤楍偺栤偄崌傢偣傪峴偄丄偦偺堄枴偵懄偟偨張棟傪峴偆傛偆偵側偭偰偄傑偡丅
東栿帪偺奺庬偺僄儔乕偼丄傎偲傫偳偺応崌娭悢偺栠傝抣偲偟偰僄儔乕抣傪曉偡偲偄偆宍偱丄
屇傃弌偟尦偵僄儔乕偺曬崘偑揱攄偟偰峴偒傑偡丅懡偔偺娭悢偼丄屇傃弌偟偨愭偺娭悢偱僄儔乕偑偁傟偽丄
帺暘偺張棟傪懪偪愗偭偰揔摉側屻巒枛傪峴偭偨屻丄僄儔乕抣傪屇傃弌偟尦偵曉偟傑偡丅
嵟廔揑偵CInterpreter撪偺MakeXXXX()傗丄GenXXXX()偱丄
FireError()偑僐乕儖偝傟丄昗弨僄儔乕弌椡偵僄儔乕儊僢僙乕僕偑弌椡偝傟傑偡丅
MakeXXXX()傗丄GenXXXX()偼婎杮揑偵yyparse()偐傜屇偽傟偰偄傞娭悢偱偡偑丄偙傟傜偺娭悢偺僄儔乕抣傪yyparse()偑僠僃僢僋偡傞偙偲偼柍偔丄抳柦揑側僄儔乕埲奜偼丄
壗帠傕柍偐偭偨傛偆偵東栿張棟傪懕峴偟傑偡丅
偙偺偨傔丄堦夞偺東栿偱僜乕僗僐乕僪拞偺暋悢偺僄儔乕傪曬崘偡傞偙偲偑偱偒傑偡丅
峔暥忋偺僄儔乕偑偁傞偲yyparse()偼yyerror()傪屇傃弌偟傑偡偑丄偙偺娭悢偼CInterpreter偺FireError()
傪僐乕儖偡傞傛偆偵側偭偰偄傑偡丅峔暥忋偺僄儔乕偼堦峴扨埵偱儕僇僶儕偱偒傞傛偆丄惗惉婯懃
傪婰弎偟傑偟偨丅
埲忋偺張棟偺棳傟傪戝傑偐偵恾夝偟偰傒傑偟偨丅 慡偰偺僋儔僗傗僀儞僞乕僼僃僀僗傪恾帵偟偨栿偱偼偁傝傑偣傫丅
|
yyparse()偼惓忢偵嵟屻傑偱僜乕僗僐乕僪撉傒恑傔傞偲丄
Interpret()偵侽傪曉偟偰張棟傪敳偗傑偡丅
嵟屻偵Interpret()偼
幚峴帪偺僨乕僞椞堟傪偡傞張棟傗丄枹夝寛偺僕儍儞僾愭偺屻杽傔張棟側偳傪峴偭偰張棟傪敳偗傑偡丅
幚峴帪娐嫬丒CMachine僋儔僗偵偮偄偰
乽傊偨傟俛俙俽俬俠乿偼僀儞僞乕僾儕僞尵岅偲偼偄偆傕偺偺丄堦扷僜乕僗僐乕僪傪拞娫揑側
僨乕僞峔憿偵東栿偟丄偦偺僨乕僞峔憿傪幚峴偡傞偨傔偺娭悢傪屇傃弌偡曽幃傪嵦偭偰傑偡丅
東栿傪巌偭偰偄偨偺偼丄庡偵CInterpreter::Interpret()偲偄偆娭悢偱偟偨偑丄
惗惉偝傟偨拞娫僐乕僪傪幚峴偡傞偺偑丄CMachine::Go()偲偄偆娭悢偱偡丅
幚峴偵昁梫側忣曬偼婎杮揑偵CMachine偺僨乕僞儊儞僶偲偟偰慻崬傑傟偰偄傑偡丅
拞娫僐乕僪傪曐帩偟偰偄傞儊儞僶偼CCode偲偄偆僋儔僗偺僀儞僗僞儞僗偺m_code偲偄偆曄悢偱偡丅
偙偺僆僽僕僃僋僩偼僐儅儞僪僴儞僪儔娭悢偺
傾僪儗僗傗丄偦傟偧傟偺娭悢偑偦偺張棟偵昁梫偲偡傞抣側偳偑攝楍偲偟偰暲傫偩僨乕僞峔憿偲
側偭偰偄傑偡丅
CMachine::Go()偼嵟弶偵m_code偺愭摢傪撉傒庢偭偰丄抣傪OP_HANDLER宆偺娭悢億僀儞僞偲偟偰丄
屇傃弌偟傑偡丅屇傃弌偟偨娭悢偑僄儔乕抣傪栠偝側偗傟偽乮侽傪曉偡側傜偽乯丄撉傒庢傞埵抲傪侾偮恑傔偰丄偦偙偺抣傪OP_HANDLER宆偺娭悢億僀儞僞偲偟偰屇傃弌偡偲偄偆張棟傪偢偭偲孞傝曉偟懕偗傑偡丅
僐乕僪椞堟偺嵟屻偵偼CInterpreter::Interpret()偵傛偭偰funcEnd()偺傾僪儗僗偑憓擖偝傟偰偄傑偡丅funcEnd()偼
栠傝抣偲偟偰-侾傪曉偟傑偡偺偱丄Go()偼儖乕僾傪敳偗偰丄僨乕僞椞堟偺屻巒枛傪峴偭偰偐傜張棟傪廔偊傑偡丅
CMachine偵偼僐乕僪椞堟偺懠偵傕丄曄悢偺抣傗幚峴偺搑拞偺寁嶼寢壥傪曐帩偟偰偍偔偨傔偵CStack<TypedData>僋儔僗偺m_stackData偲偄偆僨乕僞儊儞僶偑慻傒崬傑傟偰偄傑偡丅CStack偼僥儞僾儗乕僩僋儔僗偱擟堄偺宆偺曄悢傪僗僞僢僋偲偟偰曐帩偡傞帠偑偱偒傑偡丅曐帩偡傞懳徾偲側偭偰偄傞TypedData偲偄偆宆偼丄張棟偺懳徾偲側傞抣偲偦偺嶍彍梡娭悢傾僪儗僗偑僙僢僩偵側偭偨峔憿懱偱偡丅張棟懳徾偺抣偼奺OP_HANDLER娭悢偺拞偱擟堄偺宆偵僉儍僗僩偝傟偰巊梡偝傟傑偡丅偟偐偟偦偺抣偺尦乆偺宆偼int宆(32價僢僩惍悢宆)偵側偭偰偄偰丄傕偭偲戝偒側僨乕僞傪埖偆応崌偼丄暿偺応強偵僨乕僞傪妋曐偟偰丄TypedData偺儊儞僶偵偼偦偺億僀儞僞傪僙僢僩偡傞偲偄偆曽朄傪嵦偭偰偄傑偡丅僾儘僌儔儉偺幚峴偑廔椆偟偨帪偵偦偺億僀儞僞傪嶍彍偡傞張棟傪峴偆昁梫偐傜丄TypedData偵偼嶍彍梡娭悢偺傾僪儗僗傪曐帩偡傞儊儞僶傕愝偗傑偟偨丅CMachine::Go()偼幚峴儖乕僾傪敳偗偨屻偵丄巆偭偰偄傞慡偰偺僨乕僞偺嶍彍梡娭悢傪屇傃弌偟傑偡丅
CInterpreter::Interpret()偑僜乕僗僐乕僪拞偱巊傢傟偰偄偨曄悢傗掕悢傪丄偙偺m_stackData偵梊傔Push偟偰偍偔偨傔丄僗僞僢僋偺掙偵偼曄悢傗掕悢偺幚尰抣偑愊傑傟偰偄傑偡丅
m_stackData偼幚峴偺夁掱偱乮OP_HANDLER偵傛偭偰乯寁嶼偝傟傞堦帪揑側抣傪曐帩偟偰偍偔偨傔偵傕巊傢傟傑偡丅偙傟傜偺抣偼CInterpreter::Interpret()偵傛偭偰Push偝傟偰偄偨抣偺偡偖忋偐傜愊傑傟傑偡丅
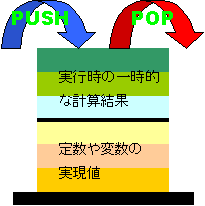 僗僞僢僋忋偺僨乕僞峔憿 |
侾偮偺僐乕僪椞堟偲丄侾偮偺僗僞僢僋椞堟偩偗偁傟偽丄戝掞偺張棟傪峴偆偙偲偑偱偒傞偺偱偡偑丄
侾偮偺僗僞僢僋椞堟偵怓乆側僨乕僞峔憿傪媗傔崬傫偱昞尰偡傞偺偑柺搢偩偭偨偺偱丄乽傊偨傟俛俙俽俬俠乿偱偼攝楍偺椞堟傗丄儖乕僾丄
僒僽儖乕僠儞僐乕儖梡偺娗棟椞堟傪曐帩偡傞偨傔偵丄摿暿側曄悢傪梡堄偟傑偟偨丅
攝楍傪曐帩偡傞偨傔偵CDynArray僋儔僗偺m_DArray偲偄偆僨乕僞儊儞僶傪梡堄偟傑偟偨丅偙偺CDynArray偲偄偆僋儔僗偼丄幚嵺偵偼CHashedList<TypedData>偺typedef偱丄僴僢僔儏昞傪儀乕僗偵偟偰幚憰偟偰偄傑偡丅CHashedList僋儔僗偺婡擻傪棙梡偟偰丄摦揑楢憐攝楍傪僒億乕僩偡傞偙偲偵偟傑偟偨丅摦揑楢憐攝楍偼丄揧帤偲偟偰惍悢偩偗偱偼側偔丄暥帤楍傕庴偗晅偗傞偙偲偑偱偒丄抣傪僙僢僩偟偨帪揰偱帺摦揑偵椞堟偑妋曐偝傟傑偡偐傜丄攝楍偺戝偒偝傪寛傔偰偍偔昁梫偑偁傝傑偣傫丅晛捠偺攝楍乮惷揑偵妋曐偝傟丄惍悢偺揧帤偟偐庴偗晅偗側偄攝楍乯偲斾傋傟偽岠棪偼悘暘偲埆偔側傝傑偡偑丄僀儞僞乕僾儕僞尵岅偼摦揑側偺偑僂儕(丠)側偺偱丄偙傟偱椙偟偲偟傑偟偨丅偨偩丄乽傊偨傟俛俙俽俬俠乿偼暥帤楍張棟婡擻偑昻庛側偺偱丄楢憐攝楍偵偡傞儊儕僢僩偼偁傑傝側偄偱偡乮敋乯丅傑偁丄偙傟偐傜偺壽戣偲偄偆偙偲偱乧(^^;
儖乕僾傗僒僽儖乕僠儞僐乕儖梡偺娗棟椞堟乮僨乕僞峔憿偲偟偰偼偳偪傜傕僗僞僢僋偱偡乯偼丄CMachine::Go()偑掕媊偝傟偰偄傞偺偲摨偠応強偵丄僼傽僀儖僗僐乕僾傪帩偮曄悢偲偟偰愰尵偝傟偰偄傑偡丅側偤CMachine偺儊儞僶偱偼側偄偺偐偲偄偆偲丄扨弮偵庤敳偒偩偭偨傝偟傑偡乮敋乯丅
奺庬OP_HANDLER娭悢偺摥偒偼婎杮揑偵偼丄偙傟傜偺僨乕僞椞堟偺娫偱僨乕僞偺弌偟擖傟傪峴偭偨傝丄僨乕僞偺僐儞僜乕儖擖弌椡丄偦偟偰張棟偺暘婒傪峴偆傕偺偱偡丅
宆僔僗僥儉丒CDataType偵偮偄偰
乽傊偨傟俛俙俽俬俠乿偱偼宆偵娭傢傞張棟偼丄東栿僄儞僕儞偱偁傞CInterpreter偑
奺CDataType僒僽僋儔僗偺僀儞僗僞儞僗偺彆偗傪庁傝傞宍偱幚尰偟偰偄傑偡丅
CDataType偼宆偵娭學偡傞張棟傪婑偣廤傔偨拪徾僋儔僗偱丄僀儞僞乕僼僃僀僗偺摑堦惈偑朢偟偄偺
偱偡偑丄戝傑偐偵偦偺婡擻傪暘椶偟偰傒傞偲師偺傛偆偵側傝傑偡丅
CDataType僒僽僋儔僗傪曋媂忋乽宆僋儔僗乿丄偦偺僀儞僗僞儞僗傪乽宆曄悢乿偲屇傇偙偲偵偟傑偡丅
- 宆摍壙敾掕
- 偁傞宆曄悢偲暿偺宆曄悢偑摍壙乮摨偠乯偐偳偆偐傪挷傋傞張棟偱偡丅 嬶懱揑偵偼CDataType::IsEquel()偲偄偆娭悢偑偦偺敾掕傪峴偄寢壥傪bool抣偱曉偟傑偡丅 偙偺婡擻偺幚尰偺偨傔丄奺宆僋儔僗偺僐儞僗僩儔僋僞偱偼丄 僋儔僗枅偵堦堄偲側傞俬俢傪妱傝怳傞張棟傪峴偭偰偄傑偡丅 IsEquel()偼偙偺俬俢傪斾妑偡傞偙偲偱丄僋儔僗偺堘偄傪擣幆偟偰偄傑偡丅 傑偨丄摨偠僋儔僗偺僀儞僗僞儞僗摨巑偱偁偭偨応崌偼丄傛傝嵶偐偄宆偺摨掕傪峴傢側偗傟偽偄偗傑偣傫丅 椺偊偽乬娭悢乭偲偄偆宆偺応崌丄乮尵岅巇條偵傛偭偰傕堘偭偰偒傑偡偑乯 娭悢柤偲堷悢偺屄悢傗宆偑堦抳偟側偗傟偽丄摨偠宆偲尒側偡偙偲偼偱偒傑偣傫丅 IsEquel()偵偼偙偆偟偨張棟傕峴偆傕偺傕偁傝傑偡丅 偟偐偟丄戝掞偺応崌偼僋儔僗偑摨偠偐偳偆偐偩偗暘偐傟偽椙偄応崌偑懡偄偺偱丄 宆僋儔僗偵偼sGetId()偲偄偆惷揑娭悢傕梡堄偟傑偟偨丅偙傟偼宆僋儔僗偺俬俢傪曉偡娭悢側偺偱丄 曉偝傟偨抣摨巑傪斾妑偡傟偽僋儔僗偺堘偄傪僠僃僢僋偱偒傑偡丅
- 掕悢側偳偺幚尰抣偺曐帩
- 宆僋儔僗偵偼僜乕僗僐乕僪拞偵掕悢抣偲偟偰昞傟傞悢抣傗暥帤楍傪曐帩偡傞偨傔偺儊儞僶曄悢偑偁傝傑偡丅CInterpreter偺儊儞僶娭悢偱掕悢抣偵揔偟偨宆曄悢偑惗惉偝傟偨屻丄 偦偺掕悢偺幚尰抣偑宆曄悢偺儊儞僶偵戙擖偝傟傑偡丅 偙偺抣偼東栿張棟傪廔偊偨屻偵丄CMachine偺僨乕僞椞堟偵Push()偝傟偨傝丄 僐乕僪椞堟偵彂偒崬傑傟偨傝偟傑偡丅
- 婰壇僋儔僗偺暘椶
- 婰壇僋儔僗偼丄偁傞曄悢乮幚尰抣乯偑丄幚峴帪偵偳偙偵抲偐傟傞偺偐傪昞偡忣曬偱偡丅 乽傊偨傟俛俙俽俬俠乿偱偼乽曄悢乿丄乽僐乕僪椞堟偺僆儁儔儞僪乿偺俀偮傪暘椶偟偰偄傑偡丅 曄悢偼僨乕僞椞堟偺掙偵愊傑傟傑偡偑丄乽僐乕僪椞堟偺僆儁儔儞僪乿偺応崌偼丄僐乕僪椞堟偵 OP_HANDLER偑捈愙庢傝崬傓偨傔偺抣偲偟偰彂偒崬傑傟傑偡丅 東栿岅偺屻張棟偺拞偱丄奺宆僋儔僗偼婰壇僋儔僗忣曬傪尦偵張棟傪暘婒偡傞傕偺偑偁傝傑偡丅 僨乕僞傪抲偄偰偍偔応強偼丄懠偵傕攝楍梡偺椞堟側偳傕偁傝傑偡偑丄 婰壇僋儔僗偵偮偄偰偼尰僶乕僕儑儞偱偼偟偭偐傝偲偟偨掕媊晅偗傪峴偭偰偍傜偢丄 侾偮侾偮偺宆僋儔僗偺幚憰偺拞偱丄揔摉偵婰壇応強傪寛掕偟偰偄傞傕偺偑懡偄偱偡丅 僗僐乕僾側偳偺奣擮傪庢傝擖傟弌偟偨傜丄傕偭偲偟偭偐傝偲掕媊偡傞昁梫偑偱偰偔傞偐偲巚偄傑偡丅
- 僐儅儞僪張棟娭悢偺採帵
- 巐懃墘嶼傗丄嶲徠乮俹倀俽俫乯丄戙擖乮俹俷俹乯丄宆曄姺丄側偳偺張棟傪CInterpreter偺儊儞僶娭悢偐傜梫媮 偝傟丄 偦偺宆偵尒崌偭偨張棟傪峴偆娭悢偺傾僪儗僗傪曉偟傑偡丅梫媮偝傟偨張棟偑丄 偦偺宆偵尒崌偭偨傕偺偱側偄応崌偼丄僄儔乕抣傪愝掕偟偰偐傜侽傪曉偟傑偡丅 屇傃弌偟懁偼侽偑曉偝傟偨応崌偼丄 偦偺宆曄悢偑帩偭偰偄傞僄儔乕抣傪庢摼偟偰丄僄儔乕傪曬崘偟傑偡丅
- 幚峴帪娐嫬偺堦晹
- 宆僋儔僗偑掕媊偝傟偰偄傞僼傽僀儖僗僐乕僾偱偼丄 幚峴帪偺張棟傪峴偆OP_HANDLER娭悢傕堦弿偵掕媊偝傟偰偄傑偡丅 奺OP_HANDLER娭悢偼丄宆僋儔僗偺SetMachine()偲偄偆娭悢偵傛偭偰愝掕偝傟傞億僀儞僞 傪捠偠偰CMachine乮幚峴帪娐嫬乯偺僀儞僗僞儞僗傪憖嶌偟傑偡丅
奺庬壓惪偗僋儔僗偨偪
乽傊偨傟俛俙俽俬俠乿偵偼東栿張棟傗丄僾儘僌儔儈儞僌尵岅偲偟偰偺婡擻傪巟墖偡傞偨傔丄壓惪偗偲側偭偰婡擻偡傞僋儔僗偑婔偮偐偁傝傑偡丅
CStr偼暥帤楍宆傪埖偆僋儔僗偱丄暥帤楍偺楢寢傗僐僺乕側偳傪乽+乿傗乽亖乿側偳偺墘嶼巕傪巊偭偰峴偊傞傛偆偵僆乕僶儘乕僪傪巤偟偰偄傑偡丅
CStringBuffer僋儔僗偼暥帤楍傪搊榐偟偰偍偄偰丄屻偐傜幆暿斣崋傪巜掕偡傞偙偲偱偦偺暥帤楍偵嶲徠偱偒傞僋儔僗偱偡丅壗偺偨傔偵巊偆偺偐偲偄偆偲丄yylex()偑愗傝弌偟偰偒偨暥帤楍傪曐娗偟偰偍偔偨傔偵巊傢傟偰偄傑偡丅yyparse()偼yylex()偐傜庴偗庢偭偨懏惈抣傪撪晹偺僗僞僢僋偵曐帩偟偰偄傞偺偱丄CInterpreter撪偺娭悢偑偦偺懏惈抣傪抦傞崰偵偼丄yylex()偼僜乕僗僐乕僪偺傕偭偲屻曽偺暥帤楍傪撉傒庢偭偰偄傞忬懺偱偡丅偙偺偨傔yylex()撪晹偺暥帤楍僶僢僼傽偺傾僪儗僗傪懏惈抣偲偟偰庴偗庢偭偰傕丄堄枴偺偁傞暥帤楍傪庴偗庢傞偙偲偼偱偒傑偣傫丅偦偺偨傔yylex()偱偼幆暿巕傪愗傝弌偟偨帪揰偱丄CStringBuffer僋儔僗偺僀儞僗僞儞僗偵偦偺暥帤楍傪搊榐偟丄懏惈抣偲偟偰偦偺幆暿斣崋傪曉偡偲偄偆張棟乮傾僋僔儑儞乯傪峴偆傛偆偵偟偰偄傑偡丅
CStack偼擟堄偺宆偺曄悢傪僗僞僢僋峔憿偱曐帩偡傞偨傔偺僥儞僾儗乕僩僋儔僗偱偡丅Push()傗Pop()側偳偺僗僞僢僋偵偼昁恵偺憖嶌傪峴偆娭悢傪梡堄偟偰偄傑偡偟丄僗僞僢僋偵愊傑傟偨僨乕僞傪攝楍偲偟偰嶲徠偡傞偙偲傕弌棃傑偡丅
CDag偼僨乕僞傪栘峔憿偵曐帩偡傞偨傔偵梡堄偟偨僋儔僗偱偡偑丄
偙偺僋儔僗偼拪徾壔偑晄姰慡偱偟偰丄栘峔憿傪曐帩偡傞偲偄偆傛傝偼丄
擟堄偺係偮偺int宆偺慻傒崌傢偣傪曐帩偡傞偲偄偆昞尰偺曽偑丄
偙偺僋儔僗偺僀儞僞乕僼僃僀僗傪惓妋偵愢柧偟偰偄傑偡丅
偙偺係偮偺int宆偼丄CDag宆偺曄悢傪巊偭偰偄傞CInterpreter偺Make乣()傗Gen乣()側偳偺娭悢偺拞偱丄
擟堄偺宆傊僉儍僗僩偟偰巊傢傟偰偄傑偡丅
CHashedList僋儔僗偼擟堄偺宆偺僨乕僞傪僴僢僔儏昞偵婰壇偡傞偨傔偺僥儞僾儗乕僩僋儔僗偱偡丅僴僢僔儏昞偼悢抣傗暥帤楍傪僉乕偵巊偭偰摿掕偺僨乕僞傪斾妑揑崅懍偵尒偮偗弌偡偙偲偑偱偒傞僨乕僞峔憿偱偡丅侾偮侾偮偺崁栚偑儕僗僩峔憿偵側偭偰偄傞攝楍偲偟偰幚憰偝傟偰偄傑偡丅専嶕傪巒傔傞帪偵丄偳偺儕僗僩峔憿乮僶働僢僩乯傪専嶕偡傞偺偐傪梊傔寁嶼偟偰偍偔偙偲偑偱偒傞偺偱丄堦杮偺儕僗僩傪摢偐傜専嶕偡傞偺偲斾傋丄暯嬒偟偰崅懍偵専嶕偡傞偙偲偑偱偒傞偺偱偡丅
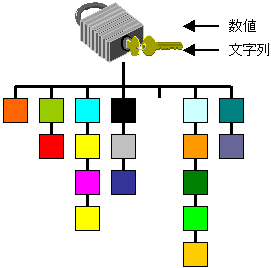 僴僢僔儏昞 |
CIdTable偼婰崋昞偲偄偭偰丄暥帤楍傪僉乕偵偟偰擟堄偺僨乕僞傪曐帩丒専嶕偺偱偒傞僨乕僞峔憿傪昞偡僋儔僗偱偡丅婰崋昞偺梫慺偲偟偰巊偭偰偄傞偺偑CIdentifer偲偄偆僋儔僗偱丄僜乕僗僐乕僪偵尰傟傞幆暿巕偲丄偦偺撪梕乮曄悢側偺偐丄儔儀儖側偺偐側偳乯傪僙僢僩偵偟偨峔憿懱偲側偭偰偄傑偡丅
婰崋昞偺幚憰偵偼僴僢僔儏昞偑偟偽偟偽巊傢傟傞偺偱偡偑丄CIdTable偼CHashedList偲偼堦愗柍娭學偵幚憰偝傟偰偄傑偡丅壗屘側偺偐偲偄傊偽丄CIdTable偺曽偑CHashedList傛傝愭偵嶌傜傟偨偐傜偱偡乮敋亊俁乯丅
僄儔乕儗億乕僩張棟
乽傊偨傟俛俙俽俬俠乿偱偼"error.h"偲偄偆僿僢僟僼傽僀儖偱丄僄儔乕儊僢僙乕僕偺暥帤楍偺攝楍偲丄懳墳偡傞僄儔乕斣崋偑掕媊偝傟偰偄傑偡丅
偙傟傜偺僄儔乕偼東栿拞偺僄儔乕偱偁偭偨応崌偼丄CInterpreter::PutError()偑昗弨僄儔乕弌椡偵僄儔乕傪彂偒弌偟丄幚峴帪偺応崌偼丄CMachine::PutError()偑僄儔乕傪彂偒弌偟傑偡丅壗屘堦偮偵傑偲傑偭偰側偄偺偐偲偄偆偲丄傾僪儂僢僋側奐敪岺掱偺帓暔乧乮敋丱敋乯丅
 尵岅張棟宯偺惂嶌偵栠傞
尵岅張棟宯偺惂嶌偵栠傞